그라파나 시리즈의 마지막 글이다.
이전 글이 궁금하다면?
2025.01.19 - [개발 아카이브] - Grafana LGTM 톺아보기 (1) - Loki 란?
2025.02.02 - [개발 아카이브] - Grafana LGTM 톺아보기 (2) - Alloy 란?
2025.02.16 - [개발 아카이브] - Grafana LGTM 톺아보기 (3) - Tempo 란?
Grafana LGTM 톺아보기 (3) - Tempo 란?
Grafana로 모니터링 서버 구축하기에서 이번엔 LGTM 중 T인 Tempo 에 대해 알아보자 이전 글이 궁금하다면?2025.01.19 - [개발 아카이브] - Grafana LGTM 톺아보기 (1) - Loki 란?2025.02.02 - [개발 아카이브] - Grafan
sienna1022.tistory.com
이번엔 LGTM중 마지막인 Mimir에 대해 이야기해보자.
Mimir 란?
역시 Grafana labs 에서 개발한 오픈소스 프로젝트이고, 고성능 장기 분산형 시계열 매트릭을 저장하는 시스템이다.
여기서 메트릭이란, 시간이 지남에 따라 변하는 데이터이다. CPU 사용률, 스레드 사용률, 메모리 등등 시간에 따라 추적하는 데이터를 말한다.
똑같이 alloy 와 같은 데이터 수집기로 부터 데이터를 전달받으면, 목적에 맞게 가공한다.

LGTM 중 공식 문서가 제일 자세하게 쓰여있다는 느낌을 받았다.
방대한 내용으로..필요한 요점만 정리해보자
Mimir의 장점은 다음과 같다.
- 프로메테우스 호환
- 고가용성
- 장기 저장소
- 빠른 쿼리
사실 마지막 시리즈라, 느끼는 점은 대부분의 LGTM 은 비슷한 요소로 구성되어있다.
단지 어떤 데이터를 담당할지가 차이 나는 것 같다. 따라서 간단히만 봐보자.
Mimir도, 전반적으로 읽기 / 쓰기로 나뉜다.
쓰기 경로
Distributor
- Prometheus or Alloy로 부터 시계열 데이터(매트릭)를 수신하는 컴포넌트이다.
- Distributor는 데이터를 샤딩해서 여러 ingester에게 병렬로 전송한다.
- 이때 Ingester의 기본 개수는 3개이다.
- 마찬가지로 Consistent hashing을 통하여 어떤 데이터를 어떤 Ingester 에 저장할지 결정한다.
- Metric name + Labels + Tenant Id => Token을 생성해서, 해시 링에 사용한다.
- 시계열 데이터를 샤딩하고 replica 개수에 따라 데이터를 복제합니다.
- 데이터의 유효성을 검증하기도 함.
- 데이터의 최대 길이라든가
- 데이터가 들어오는 속도라던가
- Quorum Consistency 읽기 / 쓰기로 일정 정족수가 넘어야 성공으로 간주함.
- N/2 + 1개의 Ingester에서 데이터를 읽은 후 결과 반환
- N/2 + 1개의 Ingester에 쓰기 성공 시, 요청을 성공으로 간주한다.
Ingester
- Distributor 가 쓰기 시, 데이터를 메모리 및 디스크에 저장한 뒤 일정 주기마다 장기 저장소(ex. S3)에 업로드함.
- Ingester의 상태
- PENDING 시작 직후 상태, 읽기/쓰기 불가
- ACTIVE 정상 운영 상태, 읽기/쓰기 가능
- UNHEALTHY Heartbeat 실패, 읽기/쓰기 불가
- LEAVING 종료 중, 읽기 가능하지만 쓰기 불가
- JOINING Hash Ring에 합류 중, 읽기/쓰기 불가
- Write De-Amplification
- Ingester는 받은 데이터를 즉시 장기 저장소에 쓰지 않고 메모리에 배치(batch) 및 압축 후 업로드
- 비용 절감 및 성능 최적화에 핵심적인 역할 수행
- 즉각적인 쓰기 시 장기 저장소에 부하가 심해져 확장성이 떨어질 수 있음
- Write De-Amplification 적용
- Ingester는 받은 데이터를 즉시 장기 저장소에 쓰지 않고 메모리에 배치(batch) 및 압축 후 업로드
- 데이터 손실 방지
- 기본 복제 계수(Replication Factor) 3 → n/2 + 1 개의 Ingester에 쓰기 성공해야 정상 처리
Compactor
Compactor는 Grafana Mimir의 블록 저장소를 최적화하는 역할
기능
- 블록 병합 (Block Compaction)
- 여러 개의 작은 블록을 큰 블록으로 병합하여 저장소 효율 향상
- 중복 데이터 제거 (Deduplication)
- 같은 데이터가 여러 번 저장되는 경우 제거하여 저장소 절약
- 정렬 및 인덱스 최적화 블록을 정렬하고 인덱스를 최적화하여 쿼리 속도 개선
- 장기 저장소 업로드 병합된 블록을 Object Stoarage에 업로드
- 가비지 컬렉션 (Garbage Collection) 불필요한 블록 및 오래된 데이터 삭제
- Compactor 동작 방식
- 블록 수집: Ingester에서 생성된 블록을 장기 저장소에서 가져옴
- 병합(Compaction): 여러 블록을 하나로 합치면서 중복 제거
- 인덱스 최적화: 병합된 블록의 데이터를 정렬하고 인덱스를 재구성
- 저장: 최적화된 블록을 다시 장기 저장소에 업로드
- 정리: 사용되지 않는 이전 블록을 삭제
읽기는 사실 다른 LGTM 에서와 동일해서 짧게 넘어가겠다.
읽기 경로
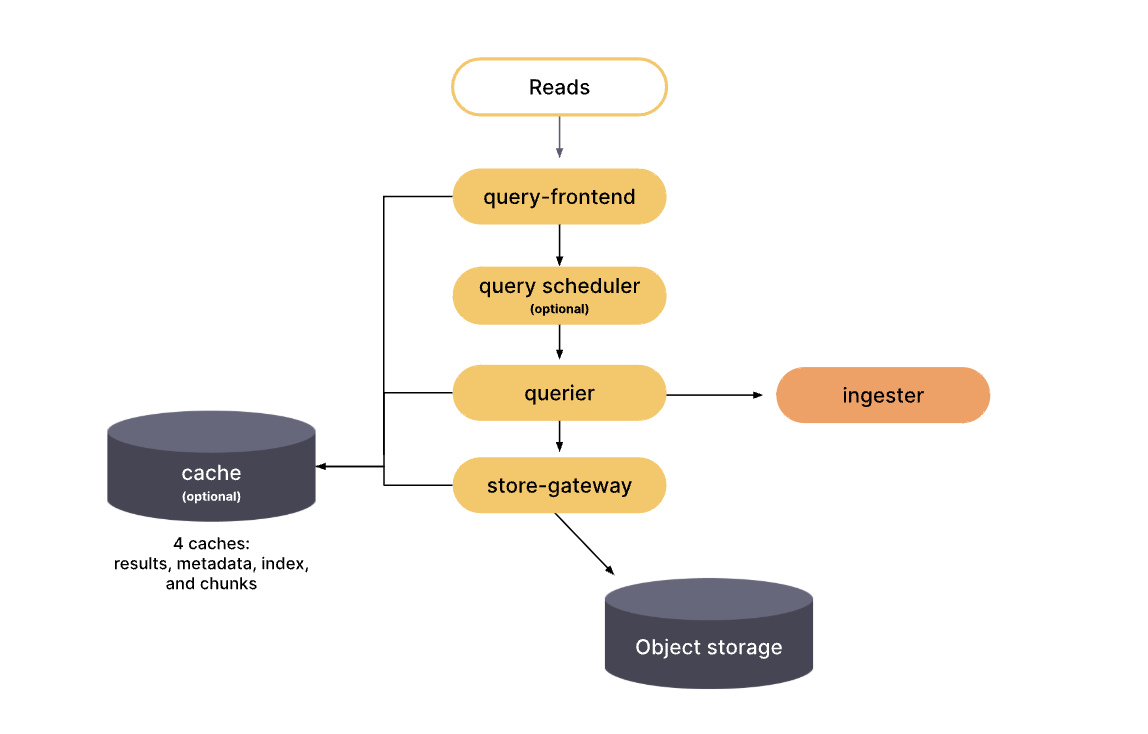
1. Grafana Mimir에서 쿼리가 query-frontend로 들어옴.
2. query-frontend는 긴 시간 범위의 쿼리를 작은 쿼리로 나눈다.
- 보통 24시간단위로 분할함.
3. 쿼리-프론트엔드는 결과 캐시를 확인.
- 캐시된 결과가 있으면 이를 반환합니다 없으면, 메모리 큐에 쿼리를 추가.
4. query-scheduler가 있으면, 큐 관리는 query-frontend 대신 query-scheduler가 함.
5. queriers는 큐에서 쿼리를 가져와 처리.
6. queriers는 store-gateways와 ingesters에 연결하여 데이터 조회.
7. 쿼리 실행 후 결과를 query-frontend로 되돌려주며, query-frontend는 이를 집계하여 클라이언트에 전달
결국 mimir 도 ingester가 읽기 / 쓰기에서 가장 많은 담당을 하기에 ingester가 가장 중요한 역할을 한다고 생각한다.
metrics-generator
참고로 시계열 데이터는 Alloy에서 직접 수집할 수도 있겠지만, Tempo에서 Mimir 데이터로 변환 시켜주기도 한다.
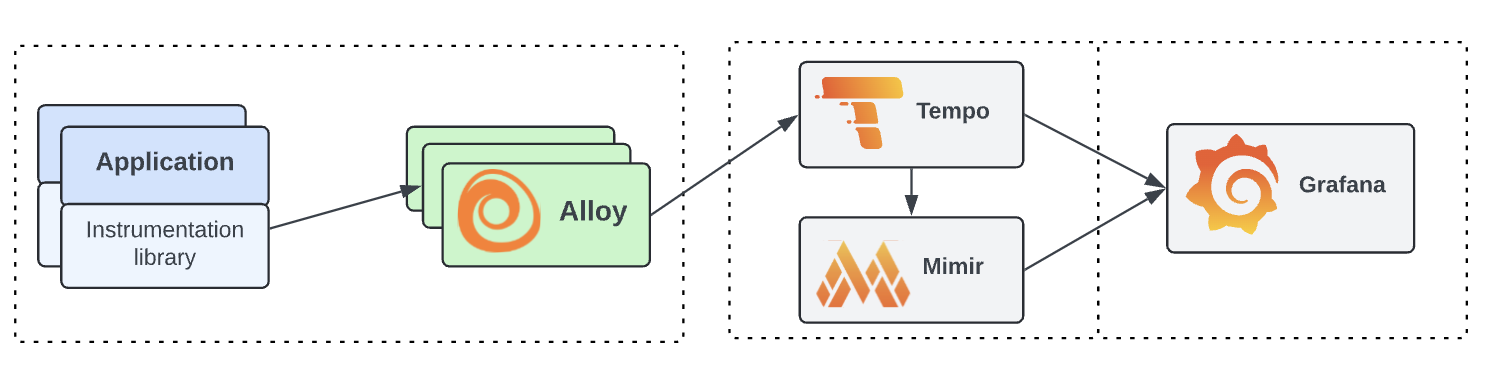
Tempo 의 컴포넌트로 수집된 Trace 기반으로 RED 메트릭을 생성해준다.
RED는 다음의 약자이다.
- Request / Error / Duration
distributor 가 받은 span을 ingester 와 metric generator 에 동시에 전달해줌.
metric-generator 는 이를 remote-write 프로토콜을 사용하여 매트릭 저장소에 저장한다.
'개발 아카이브' 카테고리의 다른 글
| Grafana LGTM 톺아보기 (3) - Tempo 란? (4) | 2025.02.16 |
|---|---|
| Grafana LGTM 톺아보기 (2) - Alloy 란? (7) | 2025.02.02 |
| Grafana LGTM 톺아보기 (1) - Loki 란? (5) | 2025.01.19 |
| 당근 채팅 시스템은 어떻게 만들까? (5) | 2024.12.08 |
| slack 파일 업로드, completeUploadExternal(),getUploadURLExternal() 사용법 (3) | 2024.11.19 |