사내에서는 서버의 트래픽을 모니터링하기 위해 datadog 솔루션을 사용하고 있다.
물론 너무너무 좋은 서비스긴 하지만, 비용이 고비용이다. 아무리 좋은 서비스도, 우선 백엔드 팀만, 장애가 났을 때만, 모니터링을 하고 있는 점에서 비용 대비 우리 상황에 맞지 않다고 생각한다. 변화가 필요하다.
팀에서는 그라파나에서 제안하는 LGTM 을 통해 모니터링 대시보드를 직접 구성하였고, 사용중이다.
그렇다면 그라파나 LGTM 을 빠삭하게 알고 있어야겠지..? 톺아보기를 시작해보자.
우선 이야기를 하기 전에, 모니터링 시스템에서 빼놓을 수 없는 철학을 알아야합니다.
Observability (관측 가능성)?
- 관측 가능성(Observability)는 시스템의 내부 상태를 외부로부터 관측하고 이해할 수 있는 능력을 의미합니다.
- 이는 현대 소프트웨어 시스템, 특히 분산 시스템에서 매우 중요한 개념으로, 성능 문제를 해결하거나 장애를 진단하는 데 필수적입니다.
그렇다면 관측을 위해 필요한게 무엇이 있을까? 대표적으로 Metrics, Traces, Logs 가 있을 것입니다.
서버에서 이를 수집하고, 유용한 데이터로 보여 주어야 합니다.
이를 위한 프레임워크들이 대거 등장했습니다.
그중 대표적인 것이 OpenTelemetry 였습니다. OpenTelemetry 는 데이터를 수집, 변환 및 백엔드로 전송하기 위한 표준화된 SDK, API 및 OTel Collector를 제공합니다. 특정 밴더에 종속되지 않은 오픈 소스입니다.
Grafana?

이 Open telemetry가 데이터를 수집하는 기반을 다지는 플랫폼이라면, 이 정보를 가지고 유용한 데이터를 시각화 해주는 것이 그라파나 입니다.
(그라파나가 왜 좋냐면, 모니터링에 필요한 모든걸 만들어 놓고 제공하기 때문인것 같다.)
Open telemtry의 배포판인 Grafana Alloy 를 통해 다양한 데이터를 수집합니다.
이후, LGTM 스택을 통해 데이터를 잘 저장하고, 쿼리하고, 보여줍니다.
LGTM?
- Loki - 로그 수집 담당
- Grafana - 대시보드 시각화 담당
- Tempo - 분산 트레이스 수집 담당
- Mimir - 시계열 데이터 수집 담당
따라서 Grafana란, 가장 최적화된 대시보드를 제공해주는 종합 오픈소스 툴킷입니다.
한눈에 모니터링 시스템을 봐보면 다음과 같을 것이다.
모니터링 하고 싶은 서버 (ex. api 서버)에 데이터를 수집해주는 alloy 를 설치한다.
모니터링 서버를 따로 띄우고 여기에 LGTM 스택을 배포하면 된다.
Loki란?

Loki 는 말 그대로, 로그를 위한 오픈소스입니다.
Like Prometheus But for Logs라는 철학을 가지고 있습니다.
프로메테우스와 유사하면서 로그를 손쉽게 조회하기 위한 철학입니다.
Alloy, Promtail 같은 agent 가 데이터를 수집하면 loki 는 이를 저장,가공합니다.
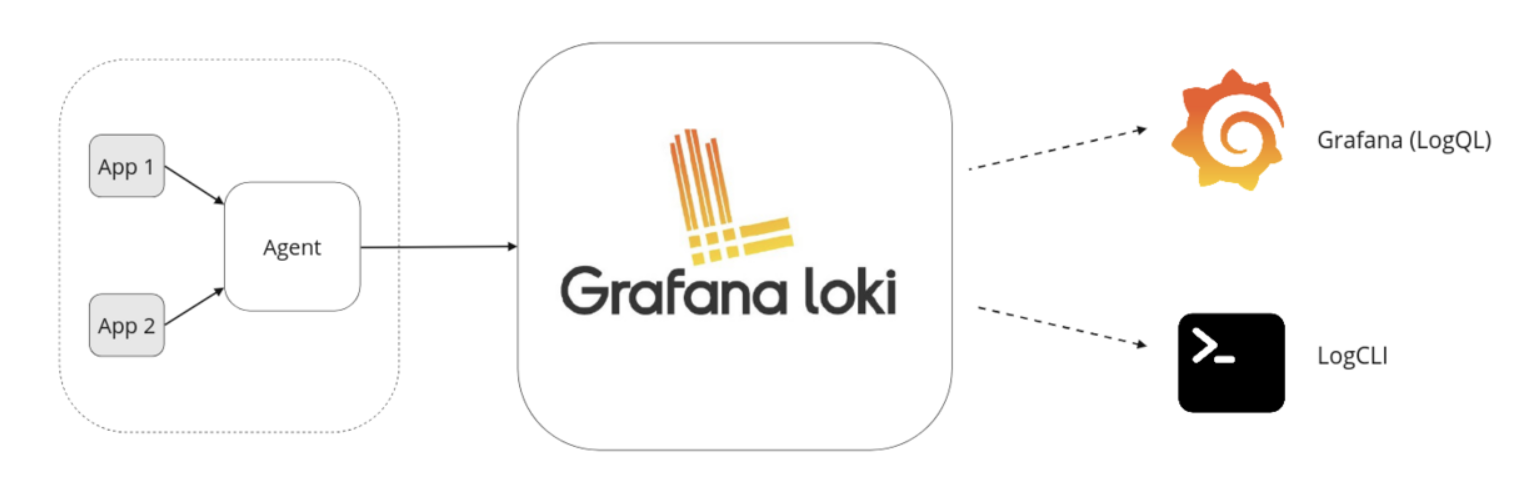
- agent : 에이전트는 로그를 스크래핑하고 레이블을 추가해서 스트림으로 변환하고 http api 를 통해 stream을 loki로 푸쉬합니다. agent로는 alloy, promtail등이 있습니다.
- Loki : 로그를 수집하고 저장하고 쿼리를 처리하는 주요 서버입니다.
- LOGQL or LOGCLI : 로그를 쿼리하거나 표시하기 위한 Grafana입니다.
일반적으로 로그를 저장하는 시스템은 Elastic Search 를 중심으로 ELK(Elastic search, Logstash,Kibana)를 사용하지만, 로키는 이에 반해 다음과 같은 특징이 있습니다.
- 확장성
- 읽기 경로와 쓰기 경로를 분리하여 독립적으로 확장 가능할 수 있습니다.
- multi -tenancy
- 단일 인스턴스를 여러 태넌트가 공유할 수 있습니다
- 효율적인 스토리지
- 고도로 압축된 청크로 저장합니다. loki 인덱스는 레이블 세트만 인덱싱하기 때문에 다른 로그 집계도구보다 상당히 작습니다.
마지막 효율적인 스토리지를 유지하는 것이 Loki 의 큰 장점입니다.
- loki에서는 로그 전체 텍스트가 아닌 메타 데이터만 인덱싱하는 방법을 취합니다.
loki는 전체 내용을 인덱싱하는 것이 아니라, stream에 관한 label 세트만 index합니다.
다음과 같은 로그 데이터가 있을 때, 메타 데이터 부분만 indexing을 합니다.
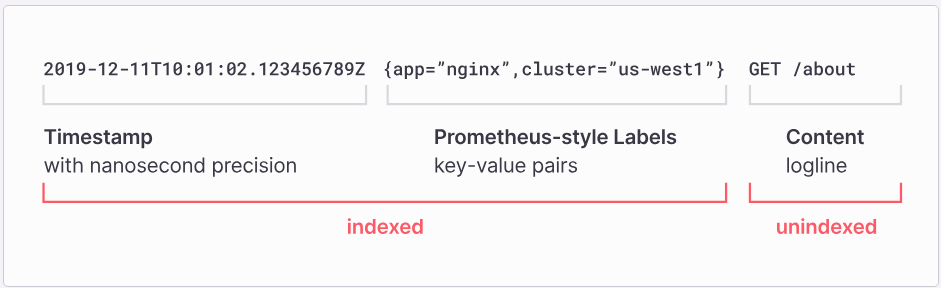

loki 자료에 굉장히 잘 나타내준 부분이 있습니다.
- 앞선 메타 데이터를 해싱하여 인덱싱하면 같은 key인 경우 같은 청크로 들어간다
- {instnace = “abc”, level = “error”} 로 시작하는 모든 라벨들은 같은 청크
- 즉 {instnace = “abc”, level = “error”} 와 {instnace = “abc”, level = “info”} 는 서로 다른 청크인 것입니다.
- 이 청크 단위로 압축되어 저장됩니다.
이로 인해 Loki에서는 메타데이터를 기반으로 로그를 빠르게 필터링한 후, 해당 조건에 맞는 로그 내용(logline)을 조회할 수 있습니다.
반면 만약 조건 없이 로그 내용을 텍스트 검색하려 적합하지 않습니다.
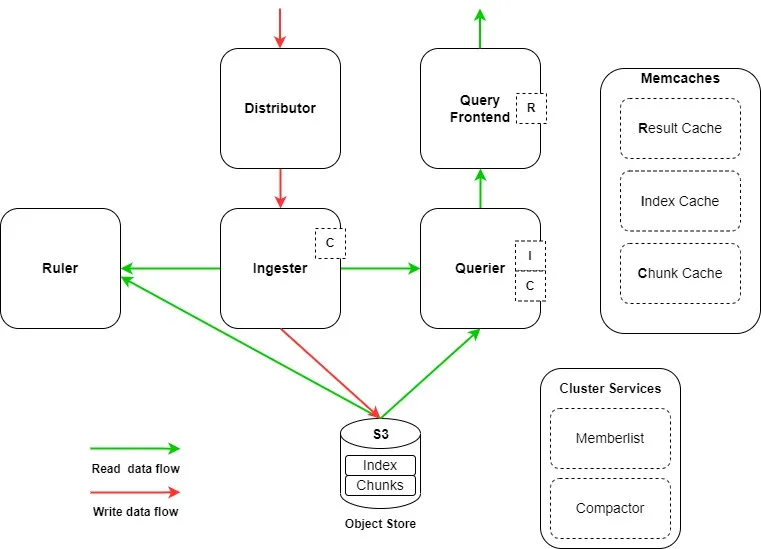
로키는 여러 컴포넌트로 구성되어있습니다.
크게 Read / Write 담당으로 나뉘는데, 이렇게 나뉘어져 각 컴포넌트 별로 확장이 가능하기에 더욱 효율적인 운영이 가능합니다.
- Wirte Component (Distributor, Ingester)
- Read Component (Query-Frontend, Query-Scheduler, Querier, Index-Gateway)
각 요소를 파헤쳐 봅시다.
- Distributor
- 클라이언트로부터 수신한 로그 데이터를 청크 단위로 검증한 후 병렬적으로 여러 Ingester들 에게 전달합니다.
- 이때 프로메테우스와 유사한 레이블을 사용하여 데이터를 검증하기에 만약 데이터 수집하는 agent가 레이블이 없다면 loki 는 적합한 선택이 아닙니다.
- Ingester
- Distributor 로 부터 받은 로그 데이터를 압축하여 Chunks 단위로 저장
- 일정 시간 후 Object Storage(ex. s3, Apache Cassandra) 로 기록합니다.
- 로그 데이터를 저장하는 대신 메타 데이터를 인덱싱합니다
- Querier
- 사용자의 쿼리를 ingestor 와 Object storage에서 처리하는데 사용합니다.
- Query Frontend
- api 를 통해 대량의 쿼리를 할 수 있게 합니다. 여러 검색은 분할 돼 작은 병렬적인 로그 읽기를 처리합니다.
- 만약 loki 를 이제 막 시작했고, querier 를 설정하기 어려운 경우 유용합니다.
결국 로그를 읽고 쓰는 것은 다음과 같이 동작하게 됩니다.
Read
- Read 요청 시 querier에서 해당 요청을 수신한다.
- querier는 ingester의 in-memory를 조회한다.
- ingester에 캐시 된 데이터가 있는 경우 querier에게 반환하고, 데이터가 없는 경우 백업 저장소(S3)에서 데이터를 조회한다.
- querier는 수신된 데이터가 중복 됐는지 확인 후 중복제거 진행하여 log를 제공한다.
Write
- distributor가 데이터를 수신한다.
- 수신된 데이터는 해시된다.
- distributor는 해시된 데이터를 ingester에게 전달한다.
- ingester는 데이터에 대해 chunk를 생성하고 저장한다.
- distributor는 데이터를 저장 완료 여부를 성공 코드로 응답한다.
loki 코드를 보면 실제로 각 코드를 볼 수 있다.(오픈소스의 장점...)
'개발 아카이브' 카테고리의 다른 글
| Grafana LGTM 톺아보기 (3) - Tempo 란? (4) | 2025.02.16 |
|---|---|
| Grafana LGTM 톺아보기 (2) - Alloy 란? (7) | 2025.02.02 |
| 당근 채팅 시스템은 어떻게 만들까? (5) | 2024.12.08 |
| slack 파일 업로드, completeUploadExternal(),getUploadURLExternal() 사용법 (3) | 2024.11.19 |
| Node.js 에서 Cpu intensive한 코드 찾아내는 법 강연 정리 (3) | 2024.10.27 |