플로니가 제공하는 서비스 중 이월 설정이 있다.
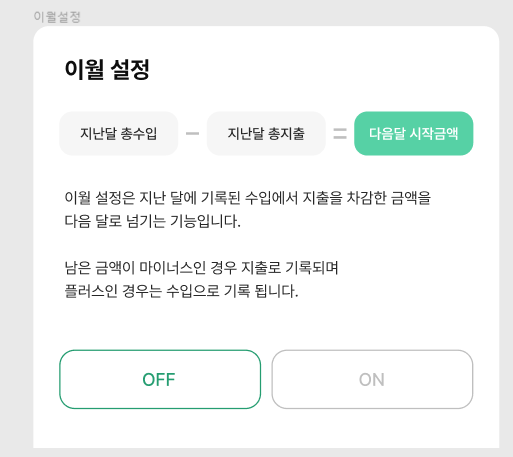
즉, 매달 1일이 되면, 모든 가계부 중 이월 설정 ON이 되어있는 가계부는
지난달 총 수입 - 지난달 총 지출 = 다음 시작 금액을 계산해서 데이터베이스에 갱신을 해주어야한다.
어떻게 해야할까?
우선 검색을 하다보니 스프링 배치라는 솔루션이 적합해보였다.
스프링 배치는 대용량 일괄 처리의 편의를 위해 설계된 가볍고 포괄적인 배치 프레임워크이다.
- 특정한 시점에 스케줄러를 통해 자동화된 작업이 필요한 경우 사용하면 좋다
딱 우리가 필요한 기능에 맞다고 본다
그렇게 몇주간 배치 공식 문서를 보며 공부를 하였고 구현을 하였다.
현재 스프링 부트 2.7.7를 사용하고 있기 때문에 우리의 Spring Batch는 2.7.7를 사용한다.
Reader - Processor - Writer로 이루어진 Job을 만들어 준다
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JobConfiguration {
private final CategoryFactory categoryCreator;
private final BookLineCategoryRepository bookLineCategoryRepository;
private final BookLineRepository bookLineRepository;
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final int CHUNK_SIZE = 10;
@Bean
public Job jpaPagingItemReaderJob() {
return jobBuilderFactory.get("carryOverJob")
.start(carryOverStep())
.build();
}
}JobBuilderFactory를 통해 Job 인스턴스를 만들어준다.
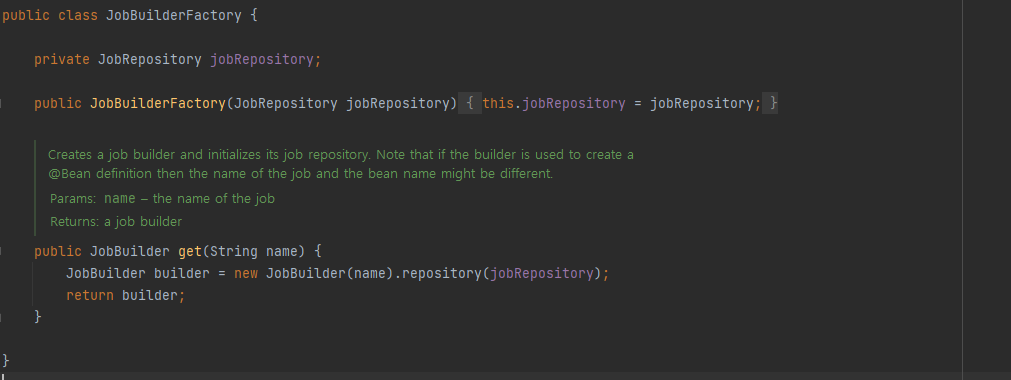
실제로 get()함수를 보면, 이름을 전달하면 builder를 통해 간단히 JobBuilder를 전달해준다.
.start()에서는 이 builder를 가지고 SimpleJobBuilder를 만든 뒤, SimpleJobBuilder의 start()를 실행한다.

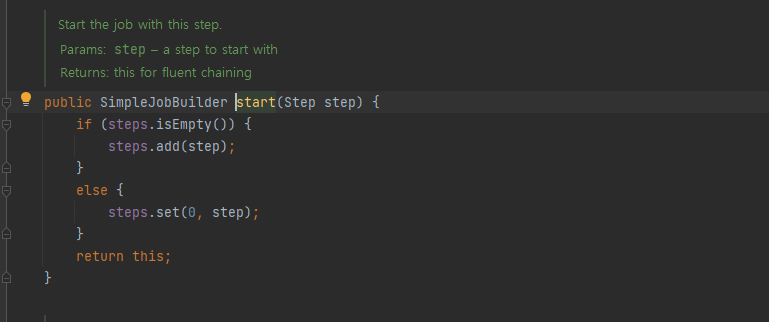
실행 되는 start()는 다음과 같다.
steps라는 new ArrayList<>() 필드에 step을 추가해서, return한다.
- JobInstance는 배치에서 Job이 실행될 때 하나의 Job 실행 단위이다.
- 하루에 한 번씩 배치의 Job이 실행된다면, 각각의 Job을 JobInstance라고 부를 수 있다.
- 오늘 Job을 실행했는데 실패했다면 다음날 동일한 JobInstance를 가지고 다시 실행하게 된다.
- Job 실행이 실패하면 JobInstance가 끝난 것으로 간주하지 않기 때문이다.
- 그러면, 이 하나의 JobInstance는 어제 실패한 JobExecution과 오늘의 성공한 JobExecution 두 개를 가지게 된다.
- 즉, 하나의 JobInstance는 여러 개의 JobExecution을 가지게 된다
그렇다면 Job에 필드인 Step은 무엇인가?
@Bean
public Step carryOverStep() {
return stepBuilderFactory.get("carryOverStep")
.<CarryOver, CarryOverInfo>chunk(CHUNK_SIZE)
.reader(jpaPagingItemReader())
.processor(jpaProcessor())
.writer(jpaPagingItemWriter())
.build();
}Step은 다음과 같이 이루어져있다 마찬가지로 StepBuilderFactory를 이용해 이름을 주면, Step Builder객체를 생성한다.
Step은 Reader -> Processor(선택) -> Writer로 이루어져있다.
Spring batch는 보통 Chunk Oriented Processing 을 사용한다. Chunk Oriented processing은 데이터를 한번에 하나씩 읽고, chunk를 만든뒤 읽은 항목수가 커밋 간격과 같으면 ItemWriter에 의해 청크가 기록된 다음 트랜잭션이 커밋된다.
즉 Chunk라는 덩어리를 만들어서 chunksize만큼 row를 읽고, size가 꽉차면 Chunk 덩어리 단위로 트랜잭션에 커밋시킨다.
이 chunk size를 미리 정해놓는다.
Chunk Size를 선언할 때는, Paging Size와 동일하게 하는 것이 좋다. chunk가 50인대 page size가 10이라면 조회를 5번 더 해야 chunk가 날라가기 때문이다.
chunk를 선언하기 위해, <Input,Output>의 타입을 선언한다.
CarryOver라는 객체를 읽고, CarryOverInfo라는 객체를 작성할 예정이다.
Reader
reader구현하는데 애를 많이 먹었다.
ItemReader에는 다양한 구현체가 있다. Cursor 기반, paging 기반 등등 있으나 프로젝트가 Jpa를 사용하고 있기에, Jpa를 사용하는게 맞다고 생각을 했다. 그리하여 JpaPagingItemReader를 사용했다.
JpaPaingItemReader는 paging 기반 JPA구현체로 EntityManagerFactory 객체가 필요하여 쿼리는 JPQL을 사용합니다.
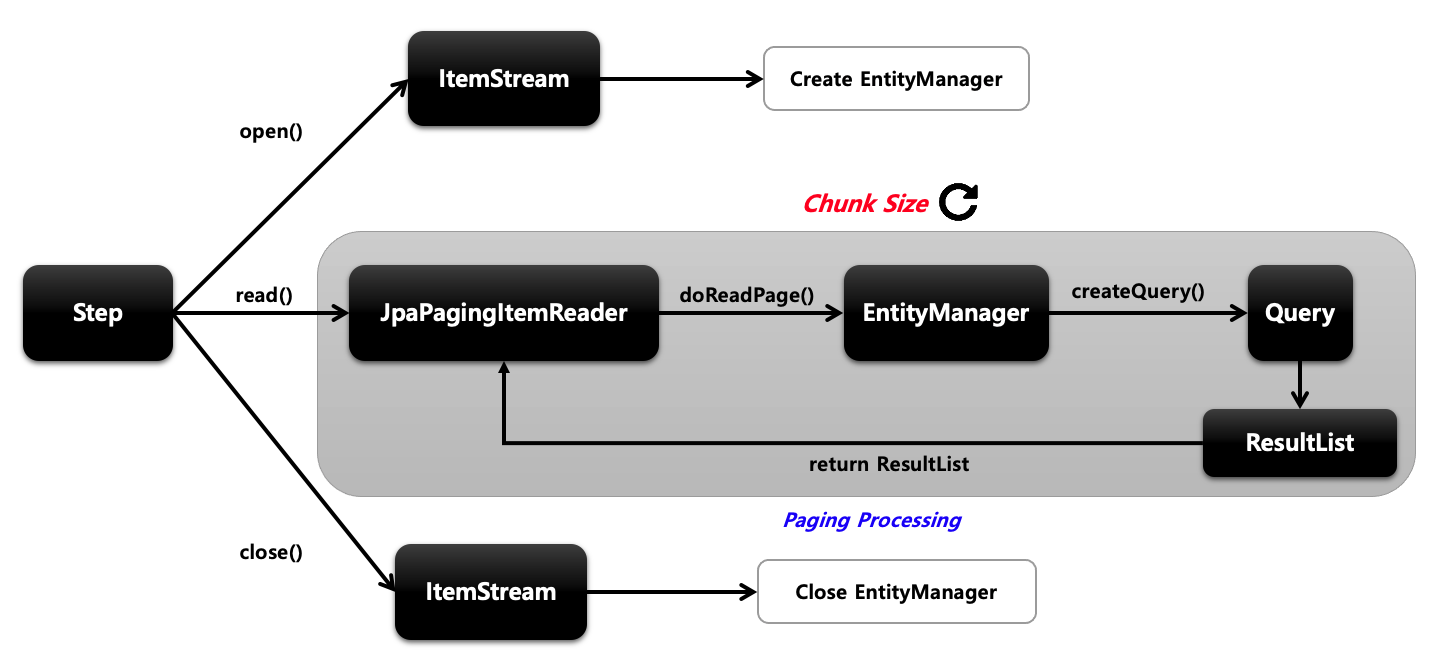
open()을 통해 entity manager를 생성한다
entity manager를 통해 쿼리를 날려 데이터를 가져옴.
이 과정을 chunk 사이즈 만큼 반복
읽을 데이터가 없다면 엔티티 매니저를 종료
@Bean
public JpaPagingItemReader<CarryOver> jpaPagingItemReader() {
HashMap<String, Object> paramValues = new HashMap<>();
paramValues.put("active", Status.ACTIVE);
return new JpaPagingItemReaderBuilder<CarryOver>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(CHUNK_SIZE)
.queryString("select new com.floney.floney.book.entity.CarryOver(book , sum(case when blc.name = '수입' then bl.money else 0 end), " +
"sum(case when blc.name = '지출' then bl.money else 0 end))" +
"from BookLine bl " +
"inner join bl.book book " +
"inner join bl.bookLineCategories blc " +
"where book.carryOver = true " +
"and bl.status = : active " +
"group by book.bookKey")
.parameterValues(paramValues)
.build();
}우선 queryDsl을 사용하다가 JPQL로 작성하려니 힘들었다. 물론 querydsl 기반 Reader 커스텀 구현체를 만들면 되지만, 기본 제공도 구현할줄 모르는데 커스텀 해봤자 의미가 있나 싶어서 우선은 주어진 상황 안에서 구현해보았다.
필요한 데이터는 해당 배치가 작동할 시점에 가계부의 총 수입, 총 지출, 가계부 정보이다. 단건 정보였으면 좋았겠지만 정보가 3개나 필요해서 어떤 자료구조를 사용해야할지 고민이 되었다.
처음에는 Object[]로 받아서, iterator를 돌려야하나 싶었지만, index로 데이터를 추출하는건 객체 지향적이지 못하다고 생각했다. 찾아보니 JPQL도 new를 통해 생성자를 사용할 수 있어, select 시 CarryOver이라는 entity를 만들어 주어, 객체를 생성해 받는데 성공했다. 객체를 받다보니, 이후에 메서드도 캡슐화하여 객체 내에서 처리할 수 있었다.
@Getter
@Service
@RequiredArgsConstructor
public class CarryOver {
private static final int STANDARD = 0;
private static final String CARRY_OVER_DESCRIPTION = "이월";
private Book book;
private Long income;
private Long outcome;
@Builder
public CarryOver(Book book, Long income, Long outcome) {
this.book = book;
this.income = income;
this.outcome = outcome;
}
}Processor
데이터를 가공할 단계이다.
이월 설정의 개념을 적용할 단계이다.
Reader를 통해 가져온 가계부 entity, 총 수입, 총 지출을 통해 연산을 해야한다.
총 수입 - 총 지출 > 0 = 수입 카테고리 분류 , 내역은 "이월"
총 수입 - 총 지출 < 0 = 지출 카테고리 분류 , 내역은 "이월"
총 수입 - 총 지출 = 0 무시
이를 계산하여 새로운 가계부 내역을 만들어내는 함수를, CarryOver entity안에 작성해주었다.
가계부 내역 만드는 건 수월하게 했는데, 문제는 가계부 내역과 OneToMany로 매핑된 카테고리(수입/지출)을 어떻게 저장할지가 문제였다.
우리 가계부는 DB에 money를 절대값으로 저장하기 때문에, writer로 넘어갔을때 이 가계부 내역이 "수입" 내역인지 "지출"내역인지 판단하기가 어려웠고, 결국 CarryOveInfo라는 객체로 CarryOver를 포장해서 assetType(수입/지출)을 표시하게끔 해결했다.
@Getter
@Service
@RequiredArgsConstructor
public class CarryOver {
private static final int STANDARD = 0;
private static final String CARRY_OVER_DESCRIPTION = "이월";
private Book book;
private Long income;
private Long outcome;
@Builder
public CarryOver(Book book, Long income, Long outcome) {
this.book = book;
this.income = income;
this.outcome = outcome;
}
public CarryOverInfo calculateValue() {
long total = income - outcome;
Hibernate.initialize(book);
BookLine bookLine = getBookLine(total);
if (total < STANDARD) {
return CarryOverInfo.builder()
.assetType(AssetType.OUTCOME)
.bookLine(bookLine)
.build();
} else if (total > STANDARD) {
return CarryOverInfo.builder()
.assetType(AssetType.INCOME)
.bookLine(bookLine)
.build();
} else {
return null;
}
}
private BookLine getBookLine(long total) {
return BookLine.builder()
.book(book)
.money(abs(total))
.exceptStatus(false)
.description(CARRY_OVER_DESCRIPTION)
.lineDate(LocalDate.now())
.build();
}
}Writer
이제 작성된 새로운 CarryOverInfo를 저장해주면된다.
private ItemWriter<CarryOverInfo> jpaPagingItemWriter() {
return CarryOverInfos -> {
for (CarryOverInfo carryOverInfo : CarryOverInfos) {
BookLine line = bookLineRepository.save(carryOverInfo.getBookLine());
BookLineCategory lineCategory = categoryCreator.create(carryOverInfo);
bookLineCategoryRepository.save(lineCategory);
line.add(CategoryEnum.ASSET, lineCategory);
bookLineRepository.save(line);
}
};
}가계부 내역을 먼저 저장해주고
가계부와 카테고리를 매핑해주어, bookLineCategory를 만들어준다.
batch를 사용할 때 test코드에서 에러가 난다
디버깅을 해보니, entity save는 되는데 entity를 찾으면 문제가 생긴다.! 도대체 왜일까
우선 가설 1. batch에서도 그렇고, Jpa에서도 entity manager를 사용해서 그런가.

Test에서는 왜 Batch가 실행되는걸까? 내가 batch 설정을 test에 안해줬는데 말이다.아 기본 클래스!!
그러면 둘이 공존해서 에러가 난다는걸 곰곰히 생각해보면, batch는 entitymanagerFactory를 사용하고 Jpa는 factory의 산출물(?)인 entity manager을 사용하는걸..!
현재 Testconfig 에서는 EntityManager를 @Persistentcontext로 주입 받고 있었다.
@PersistentContext
@PersistenceContext로 지정된 프로퍼티에 아래 두 가지 중 한 가지로 EntityManager를 주입해줍니다.
- EntityManagerFactory에서 새로운 EntityManager를 생성하거나
- Transaction에 의해 기존에 생성된 EntityManager를 반환해줍니다.
흠,. EntityManagerFactory는 한개만 생성되는 것을 알고 있다.
그렇기 때문에, Batch에서 주입 받는 entityManagerFactory와 PersistentContext에서 실행하는 PersistentContext는 같은 아이임에 농후하다.
그렇다면 entityManagerFactory가 정상적으로 생성(?)이 되지 않았을 것이다.
생각해보니 @DataJpaTest를 사용하고 있어서
dataJpaTest는 jpa 관련 bean만 주입해주기에 batch에 필요한 bean들이 주입이 안되서 결국 entityManagerFactory가 없던 것 아닐까?
그리하여 @SpringBootTest 어노테이션으로 바꾸어주었더니, 성공
그런데 나는 이 작은 단위테스트에 굳이 SpringBootTest로 무겁게 만들고 싶진 않았다.
그래서, 함께 공생할 방법을 찾아 보다가, 그런 글을 발견했다.
[Spring] 스프링 부트 설정/테스트 작성 시의 주의사항(스프링 부트 테스트가 오래 걸리는 이유) - MangKyu's Diary (tistory.com)
[Spring] 스프링 부트 설정/테스트 작성 시의 주의사항(스프링 부트 테스트가 오래 걸리는 이유)
스프링 부트가 제공하는 테스트는 모두 통합 테스트입니다. 그러다보니 스프링부트 설정이나 테스트 코드를 작성할 때 주의해야 하는 부분들이 있습니다. 이번에는 테스트가 느려지지 않도록
mangkyu.tistory.com
오예
그렇다면, 블로그 글 처럼 @EnableBatchProcessing을 다른 클래스로 뺴니깐 해결할 수 있었다.
무슨 문제인지 코난 처럼 추리하다가 결과를 알게 되서 기쁘다
결과를 알고보니, 해당 깃 issue처럼 안된 사람이 은근 있었나보다…
해결해서 다행이다…

@EnableBatchProcessing doesn't work with @DataJpaTest · Issue #10703 · spring-projects/spring-boot (github.com)
Spring Batch - ItemReader | Backtony
'Floney' 카테고리의 다른 글
| [플로니] 데이터 동시성 제어하기 (0) | 2023.10.08 |
|---|---|
| [플로니] 서버야 왜 자꾸 죽니 (3) | 2023.10.03 |
| [플로니] 초기화된 캘린더 응답 방식 포함 시켜 만들기 (0) | 2023.05.30 |
| [플로니] default 설정을 했는데 null이 나와요 (0) | 2023.05.09 |
| 플로니 - 끝나지 않은 카테고리 삽질기(상속관계 @Builder) (0) | 2023.04.30 |