https://tv.naver.com/v/23649793
NAVER D2
일본에서도 VOD를 빠르게 업로드하고 재생할 순 없을까
tv.naver.com
2021 deview 컨퍼런스를 보고 내용과 느낀 점을 정리해 본다.
이번에 본 컨퍼런스는 [일본에서도 vod를 빠르게 업로드하고 재생할 순 없을까?]의 주제였다.
이걸 고른 이유는 vod 서비스는 어떻게 개발되는지 하나도 지식이 없어서, 보게 되었다.
해당 컨퍼런스를 발표한 부서는 네이버 etech이다.
etech는 포토 오디오 비디오의 생산부터 클라우드까지 전반적인 워크플로의 기술 연구와 개발을 담당하는 부서라고 한다.
즉, 사용자가 영상을 업로드하고, 그걸 클라우드에 적재하고 영상을 보여주는 일련의 모든 과정을 담당하는 부서라고 이해했다.
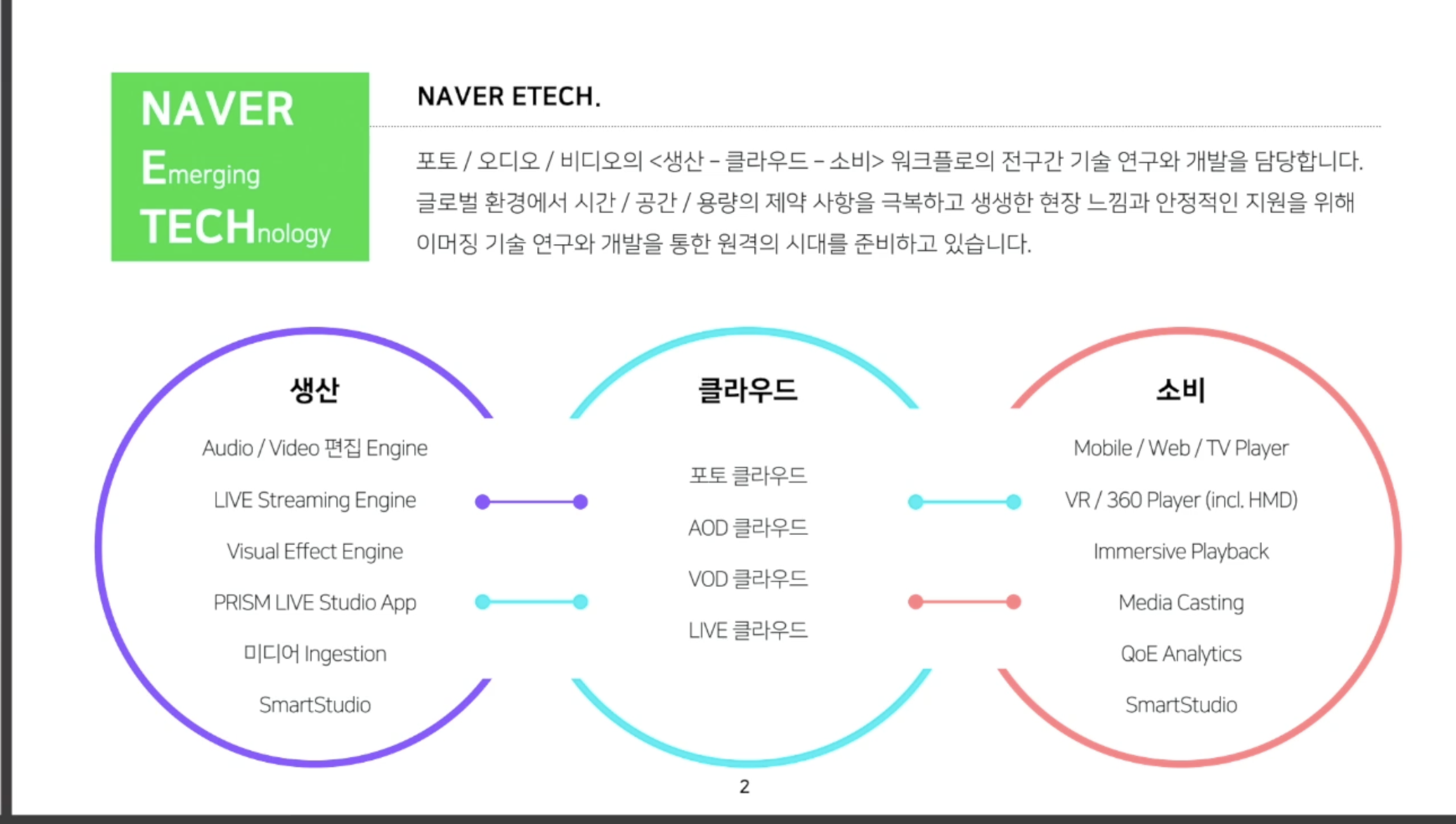
이번 발표자님은 그 과정 중 클라우드에서 - VOD 클라우드 담당이시다.
발표를 한 문장으로 요약하자면,
원래는 vod 클라우드의 저장 스토리지가 한국에만 있어서, 여러모로 글로벌 서비스가 어려워, 일본(다른 region)에 그 클라우드를 구축한 이야기였다.
1. 문제 정의 - 왜? 하게 되었는지
- 동영상 업로드는 해마다 33% 씩 증가 중
- VOD는 어디서나 필요함(쇼핑, 뉴스 등등)
- 일본은 가까운데 한국 리전 사용하면 안 돼?
- 레이턴시 이슈(크리티컬 하진 않았음)
- 비즈니스 법적 이슈(사전 예방 차원, 국외의 개인정보를 국내에 보유하고 있기에 언젠가 문제가 생기지 않을까?)
- 무엇보다, 한국 리전에만 vod 처리에 필요한 transcoder, stroage 가 있음
- 운영 비용과 트래픽은 비례하게 됨(트래픽이 바다를 지나면 더 비싸짐)
결국 가장 큰 문제는 vod 업로드는 세계에 있지만, 스토리지가 한국에 있어서, 모든 vod가 한국을 지나쳐야 한다.
2. 무엇을 설계했는지? : 일본에도 한국과 같은 VOD 클라우드를 구축하자
[일본 리전 목표]
1. 앤드 유저(실제 사용자)가 접근성이 좋게 하자
2. 클라우드 표준을 정립하자
3. vod 서비스를 제공받는 많은 서비스에게 기존과 같은 앤트리 포인트를 제공하고 변경을 최소화하자.
Region 분리 시 고민거리가 있었다고 한다 : region과 region이 어디까지 통신을 해야 할지?
인프라 별로 어디까지 영향을 주는지 범위를 정의했다.

결론 : OverRegion을 최대한 줄이자
- 최대한 로컬 region에서만 가능하도록
- 트래픽이 서로 통신되면 레이턴시가 늘어진다
- OverRegion에서는 한 리전에서 장애가 생기면, 영향 범위가 크다 [중요]
실제 프로세스로는, vod 업로드 시 메타 데이터는 로컬 region에서만 가지고 있는다.
즉 한국에서 vod를 올리면 한국 region내의 vod 디비에 저장하고, 일본에서 vod를 올리면 일본 region내의 vod 디비에 저장한다.
그럼 한국인이 올린 영상을 일본인이 못 봐?
=> 그건 아님. VOD 업로드는 로컬 리전으로, 재생은 글로벌하게
일본인이 재생 버튼을 누르면, 플레이어는 CDN을 찾고 CDN은 메타데이터를 찾는다.
3. 대용량 트래픽의 운영을 어떻게 했는지?

[vod 특징]
- 매우 용량이 큼, Network Throughput TPS가 큼.
- VOD의 생명 주기 : 업로드 -> 트랜스 코딩 -> 재생 -> 삭제
- 업로드 : 업로드 영상을 공용 스토리지로 복사
- 부하 시 해결책 : 스케일 아웃으로 대응 가능
- 트랜스 코딩 : workflow 제어, DB 저장, 스토리지 저장, 트랜스 코딩, 헤더 추출, 섬네일 추출 등등 할게 많음.(무려 10분짜리 영상은 5분 정도 걸림)
- 부하 시 해결책 : 쉽지 않음 / Event Driven Atchitecture
- 재생 : 스트로지에서 output 파일을 플레이어로 재생
- 부하 시 해결책 : 캐싱
- 삭제 : 쓰임새가 없어진 삭제
- 부하 시 해결책 : 배치로 삭제
- 업로드 : 업로드 영상을 공용 스토리지로 복사
Etech는 이를 위해 Event Driven Architecture를 선택했다.
즉, 비동기로 시행하는 것이다.
하지만, 그 안에서도 몇 가지 장치를 심었다.
1. 우선순위 조절
Job에게도 우선순위가 있다.
RabbitMQ의 Priority를 사용한다.
ex. 손흥민 영상이 인기 많다면, Priority를 높여서 먼저 처리할 수 있도록 한다.
* 실시간으로 어떤 영상이 더 중요한지 어떻게 알지? AI를 사용하나
2. 특정 서비스의 리소스 과다 점유 방지
프로모션 이벤트, 교회가 끝날 때쯤 그런 관련 영상이 pool을 다 사용해 버림 양으로 독점한 느낌
그럴 때 RabbitMQ의 quota와 deadLetter를 사용해서, 임계치를 지정한다고 한다.
* 이 내용은 모르겠어서, 나중에 다시 봐야겠다
4. 라우팅을 어떻게 구현했는지?
스토리지를 한국에만 저장하게 되었다가, N개의 리전에 저장하게 되었다.
4-(1). 누가 라우팅을 담당하는가?
네이버 서비스(쇼핑, 뉴스) vs vod 클라우드
정답 : vod 클라우드
- vod 클라우드가 관리한다면 서비스는 신경 쓸 필요가 없음
- 각 서비스 릴리즈가 더 빨라지고, 서비스 커뮤니케이션 비용 절감이 된다.
- 책임과 역할이 확실히 분리된 선택 같다고 생각한다.
4-(2). Gateway
게이트웨이(GW)는 모든 요청이 들어오는 통로로 사용됨.
서버 레이어 중에서 변경이 가장 적은 부분.
GSLB를 사용한 라우팅
- 일반적으로 사용자가 요청하면 DNS 서버가 가장 가까운 게이트웨이(GW)로 라우팅.
- 이를 통해 DNS에 소요되는 시간과 비용을 절감 가능.
영상 고유키 기반 라우팅
- 라우팅은 영상 고유키(Video ID)를 기반.
- 예를 들어, POST {url}/videoId처럼 요청 URL의 끝에 Region 정보를 포함시킴으로써 해당 지역의 서버로 트래픽이 분배됨.
- 과거 영상 데이터의 라우팅은 어떻게 처리하지?라고 속으로 생각 중이었는데, 이에 대한 해결책으로 Prefix 방식이 도입되었다.
- 예: 한국 Region에 저장된 영상은 /kor/{url}과 같은 방식으로 Prefix를 부여하여 요청
Spring Cloud Gateway와 Eureka를 사용했다
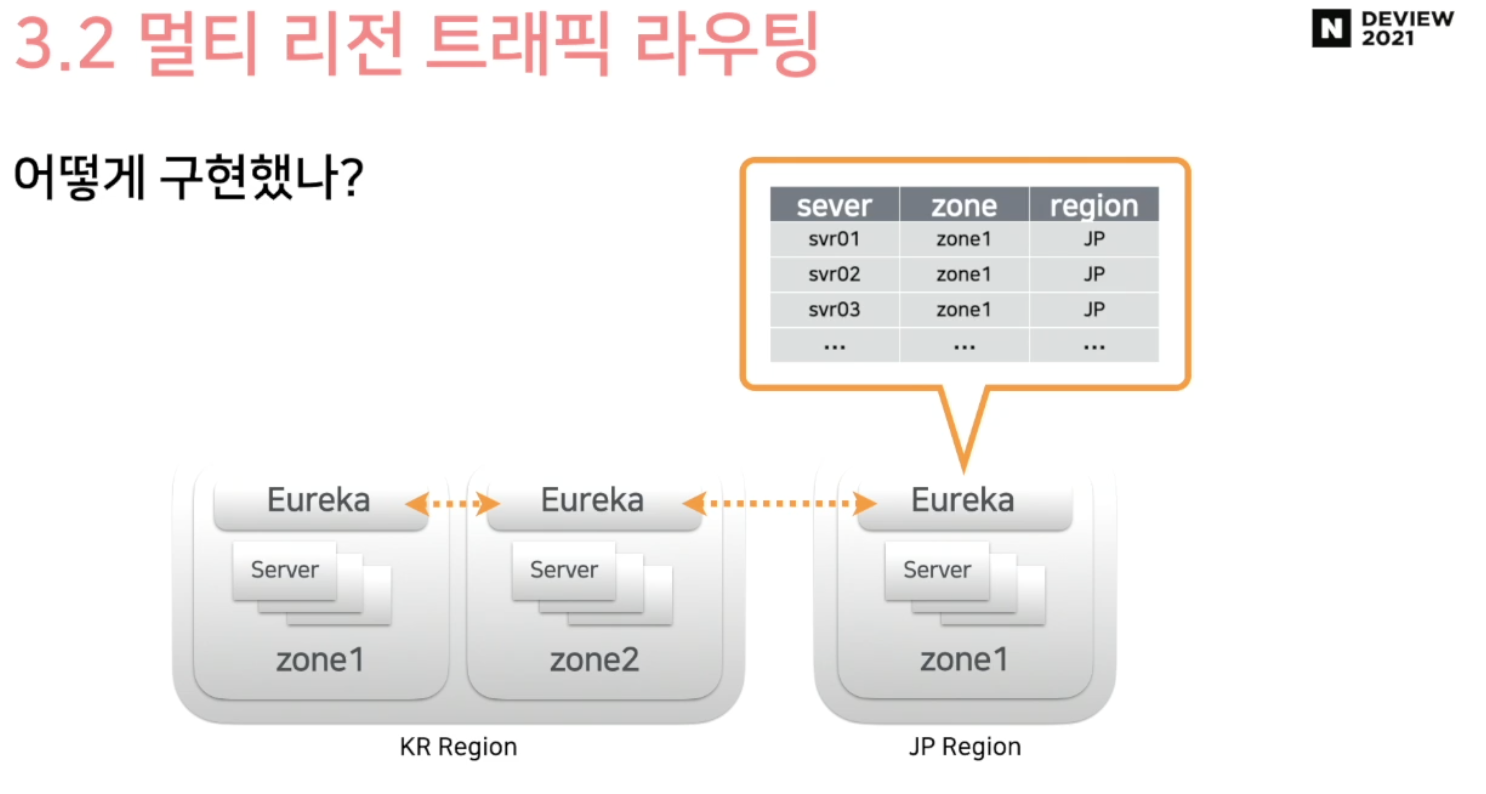
그림처럼 Eureka를 각 region에 놓아서 각 region 서버 정보를 모두 들고 있는 상태라면
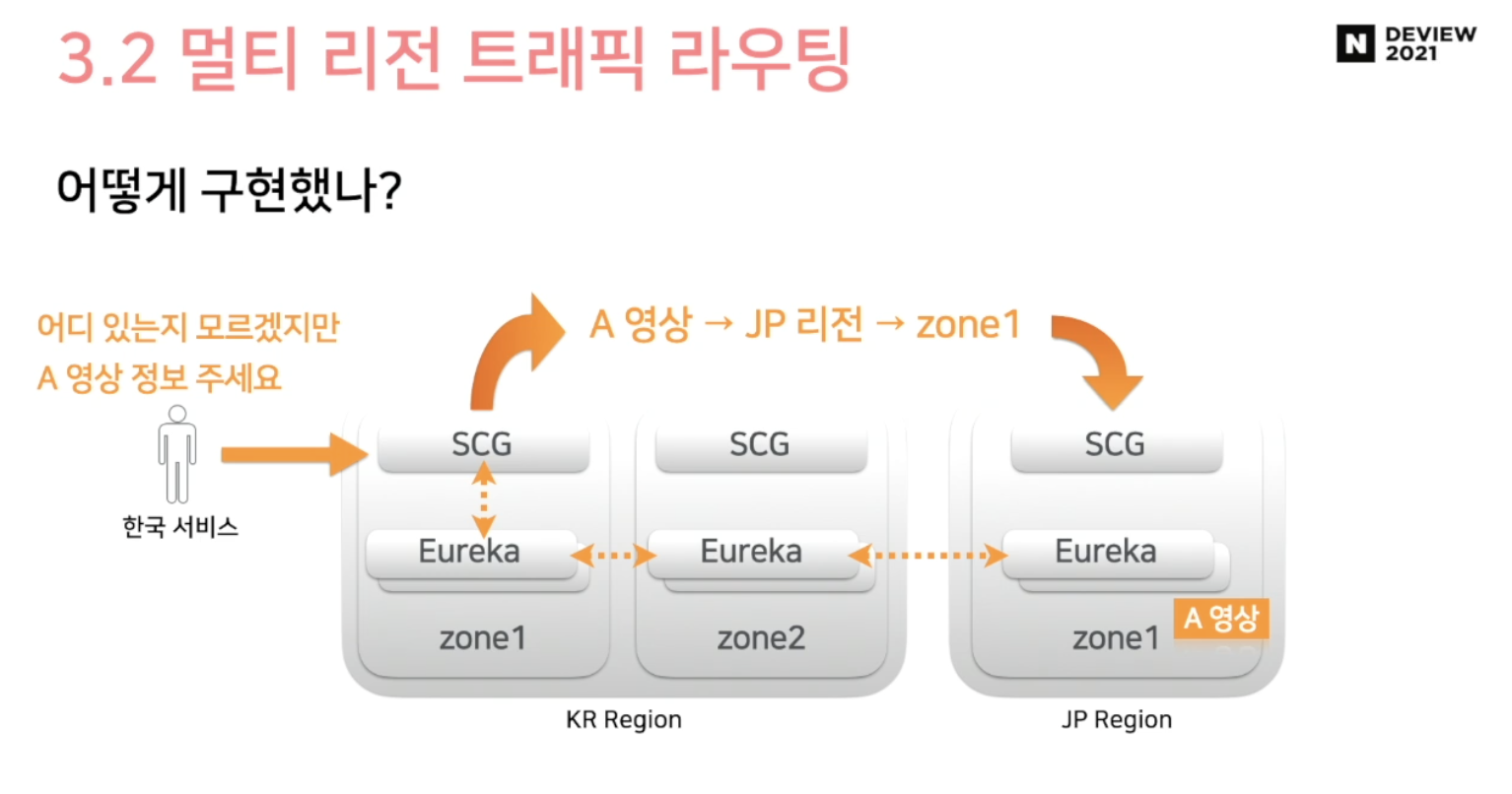
사용자 요청 -> DNS -> 가장 가가운 GW 한국 -> 게이트웨이 path 분석 -> 일본 유레카로 요청 -> 유레카가 직접 서버 ip주소로 요청 시도의 프로세스를 갖는다.
5. 안정성 보장은 어떻게 하지?
1. 테스트 케이스 수백 건씩
2. Jenkins Job
3. Slack Alarm
통합 테스트를 해도 완벽하진 않음 : 각 장애 상황에 대한, 대응 방식을 기술함.

가장 중요하게 생각한 부분 : 각 region의 고립
일본 서비스에 장애가 있다고, 한국에 장애가 나면 안 됨
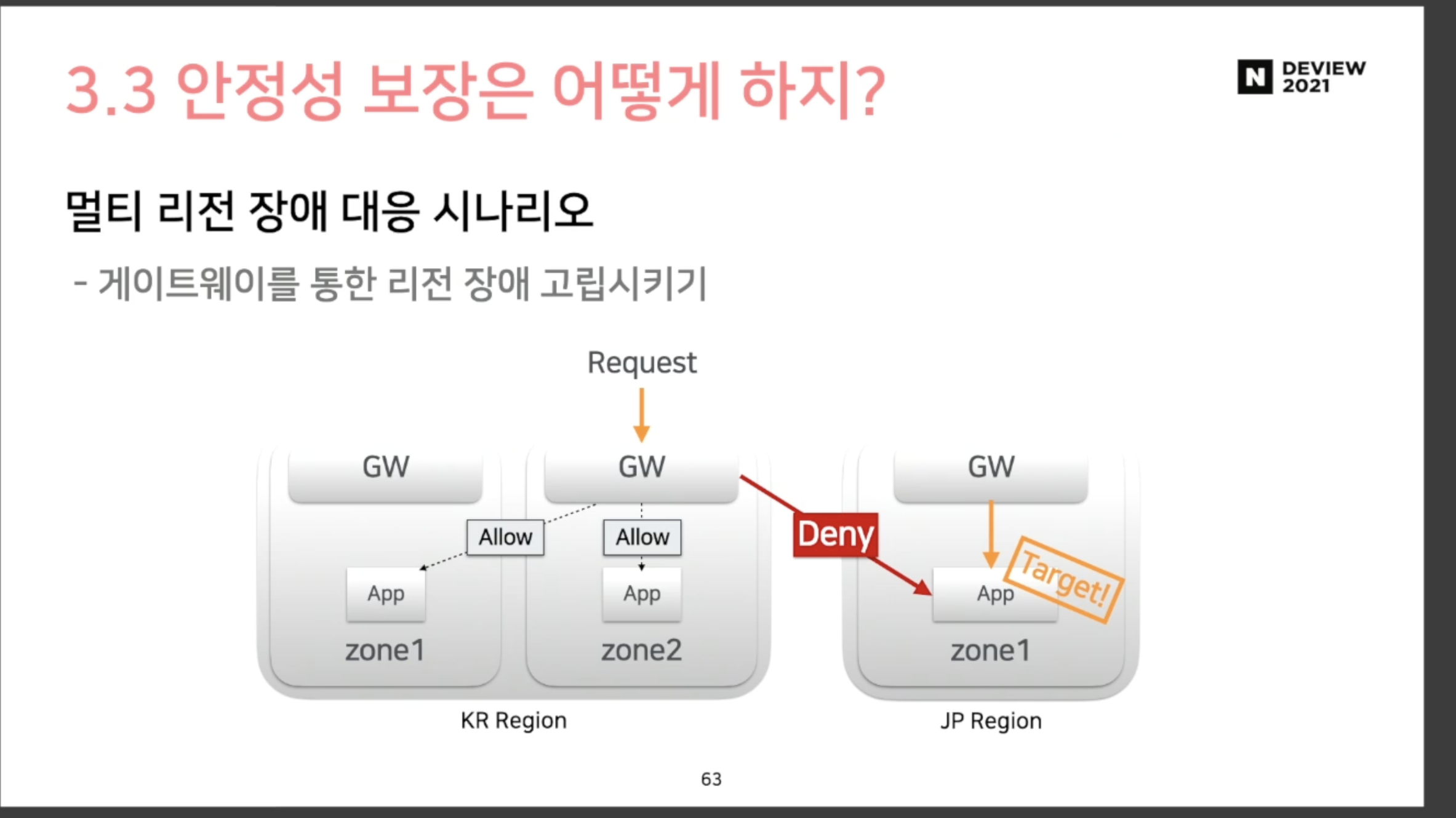
게이트웨이를 통해서만, 리전 장애 고립시키기
무조건 게이트웨이를 통해서만 정보를 주고받아야지만, 고립시킬 수 있음
[적용 후기]
굳 - 수행시간이 굉장히 빨라짐
아쉬운 점
- 운영 비용이 증가
- 게이트웨이 복잡도 증가 => 라우팅도 추가되고, 리전 분기 로직도 추가되고.. 아 너무 복잡해졌다.
새로운 아키텍처는 요구 사항, 플랫폼 구조, 비용 등을 종합적으로 고려하여 판단해야 한다.
6. 나의 후기
해당 영상을 보면서, 이전에 설계했던 멀티태넌시 SaaS 모듈이 많이 생각났다.
그때도 서로 다른 region에 영향이 있는 상황을 방지하기 위해, 인프라 구성에 있어서 Pooled 방식과 Silo 방식을 고려했었다.
더불어서, 요청을 라우팅 하기 위해 url 기반 라우팅을 사용했는데 유사해서 놀랐다.
2024.06.29 - [분류 전체보기] - 멀티태넌시 SaaS 모듈 설계 썰 푼다.txt
하지만, 아쉬웠던 점은 내가 설계한 모듈은 모듈 내부에서 게이트웨이 역할도 같이 했다.
미들웨어로 분리하긴 했으나, 게이트웨이 서버를 하나 더 띄울 수 있다면 역할과 책임이 분리되지 않을까 싶다.
또 우리 회사 사내 서버들은 서로 서비스를 요청하고 받기 위해 연결된 경우가 많다.
직접 서버 주소를 알고 요청을 직접 하다 보니, 한쪽 서버가 변경되었는데 한쪽이 몰라서 에러가 난적이 종종 있다.
유레카 같은 서비스 디스커버리로 ip 주소가 바뀌는 등의 관리 포인트를 모아두면, 이런 공수가 적지 않을까 다시금 느낀다.
하나 더 실무에서나, 늘 고려하지 못했던 부분이 있었는데 바로 장애 대응 시나리오를 생각한 적이 없단 것이다.
장애를 방어하거나 예방하는 시나리오는 늘 생각했다. 캐싱을 해놓거나 슬랙 알람을 설정하거나 말이다.
하지만, 막상 장애가 나면 어쩔 건데? 에서 항상 장애가 났네.로 끝나는 아키텍처를 설계한 것 같다.
장애가 났을 때, 위 영상처럼 다른 zone으로 라우팅 하거나 새로운 서버를 올리는 등 대응 방안을 고려할 줄도 알아야겠다.
Event Driven 도 잘쓰면 참 좋은 아키텍처라고 생각한다. 플로니 가계부 개발하면서 종종 썻지만, RabbitMQ 같이 인프라를 이용하진 않았기에, 이후에 관심있게 보고 공부해봐야겠다.
'개발 아카이브' 카테고리의 다른 글
| Grafana LGTM 톺아보기 (1) - Loki 란? (5) | 2025.01.19 |
|---|---|
| 당근 채팅 시스템은 어떻게 만들까? (5) | 2024.12.08 |
| slack 파일 업로드, completeUploadExternal(),getUploadURLExternal() 사용법 (3) | 2024.11.19 |
| Node.js 에서 Cpu intensive한 코드 찾아내는 법 강연 정리 (3) | 2024.10.27 |
| 쿠버네티스란? feat. 데이터 처리도 이제는 컨테이너로, 우아한형제들의 데이터플랫폼 혁신 (5) | 2024.10.13 |