Elastic Search 가이드 북 - 시스템 구조, Analyzer
잇츠 스터디 4기에서 elastic search 스터디를 진행 하면서, 내용을 정리한 글입니다.
2025.03.30 - [개발 아카이브] - Elastic Search 가이드 북 - QueryDSL 정리
지난번에는 실질적으로 데이터를 어떻게 조회하는지 알아봤다면,
이번에는 elastic search가 데이터를 어떻게 저장하고 있는지 그 구성과 원리에 대해 알아보자.(사실 가장 궁금했던 부분이다)
시스템 구조

1. 클러스터
- 여러개의 노드로 이루어진 elastic search의 전체 시스템을 말함.
- 최소 하나 이상의 노드로 구성된다.
- 서로 다른 클러스터는 독립적인 시스템으로 유지됨.
- 비유 : 서울시 전체 도서관 네트워크
2. 노드
- 클러스터 내의 개별 서버
- 역할에 따라 마스터 / 데이터 / 인제스트 노드로 구분됨.
- 비유 : 개별 도서관
- 마스터 : 도서관 본부(서울시 도서관 전체 관리)
- 데이터 : 실제 책을 보관하는 도서관
- 인제스트 : 도서관 사서
- 하나의 물리 서버마다 하나의 노드를 실행하는 것을 권장함.
- 하지만, 하나의 물리적인 서버 안에 여러개의 노드를 실행하는 것도 가능함.
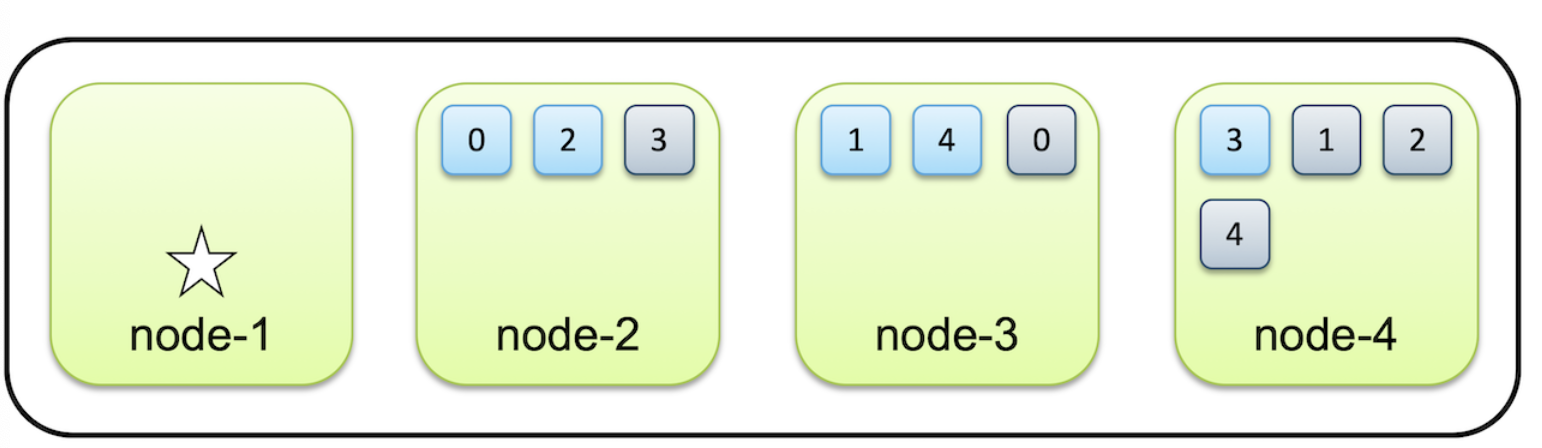
2-1. 마스터노드(Node 1)
인덱스의 메타 데이터, 샤드의 위치와 클러스터 상태 정보를 관리하는 역할
마스터 노드 외의 모든 노드들은 마스터 후보 노드(master eligible node)
기존 마스터 노드가 다운될 시, 후보 노드중에서 대신 수행을 함. (이미 항상 데이터 전체 공유를 하고 있음)
하지만 만약 클러스터가 커져서 노드와 샤드 개수가 많을 시 해당 역할을 하기 버거워, 이때는 후보 노드를 따로 선정하는 게 성능에 도움이 됨.
여러 대의 서버가 하나의 클러스터를 구성하게 된다.

같은 물리적인 서버라도 cluster.name 이 동일하지 않으면 논리적으로 서로 다른 클러스터로 실행된다.
노드들의 포트 정보
http 포트 : 9200~9299
노드끼리 교환을 위한 tcp 포트 : 9300~9399
3. Discovery
- 노드가 처음 실행될 때, 네트워크 상의 다른 노드들을 찾아 하나의 클러스터로 바인딩하는 과정
- 신규 노드가 추가될 때 기존 네트워크에 합류하려면, 어느 노드가 운영 중인지를 알아야 함.
- 디스커버리 과정
- discovery.seed_hosts 설정에 있는 주소 순서대로 노드가 있는지 여부를 확인
- 노드가 있는 경우 : cluster_name 확인
- 일치하는 경우 > 같은 클러스터로 바인딩 > 종료
- 일치하지 않는 경우 > 1로 돌아가서 다음 주소 확인
- 만약 끝까지 찾지 못한 경우 새로운 클러스터를 실행한다
- discovery.seed_hosts 설정에 있는 주소 순서대로 노드가 있는지 여부를 확인
4. 인덱스
비유 : 장르(소설, 역사 과학)
검색 데이터를 저장하는 논리적인 공간
단일 데이터 단위인 document를 모아놓은 집합
rdbms의 테이블과 같은 논리적인 구조
4. 샤드
비유 : 책장
인덱스를 여러 개로 분할하여 저장하는 단위
인덱스는 샤드라는 단위로 분리되고 각 노드에 분산돼 저장됨.
샤드의 개수는 인덱스를 처음 생성할 때 지정함.
샤드가 많으면 좋은가? => 아님.
- 쿼리 수행 시 샤드의 개수만큼 cpu의 스레드를 사용
- 샤드가 많을수록 리소스를 많이 사용함
5. 프라이머리 샤드와 복제본
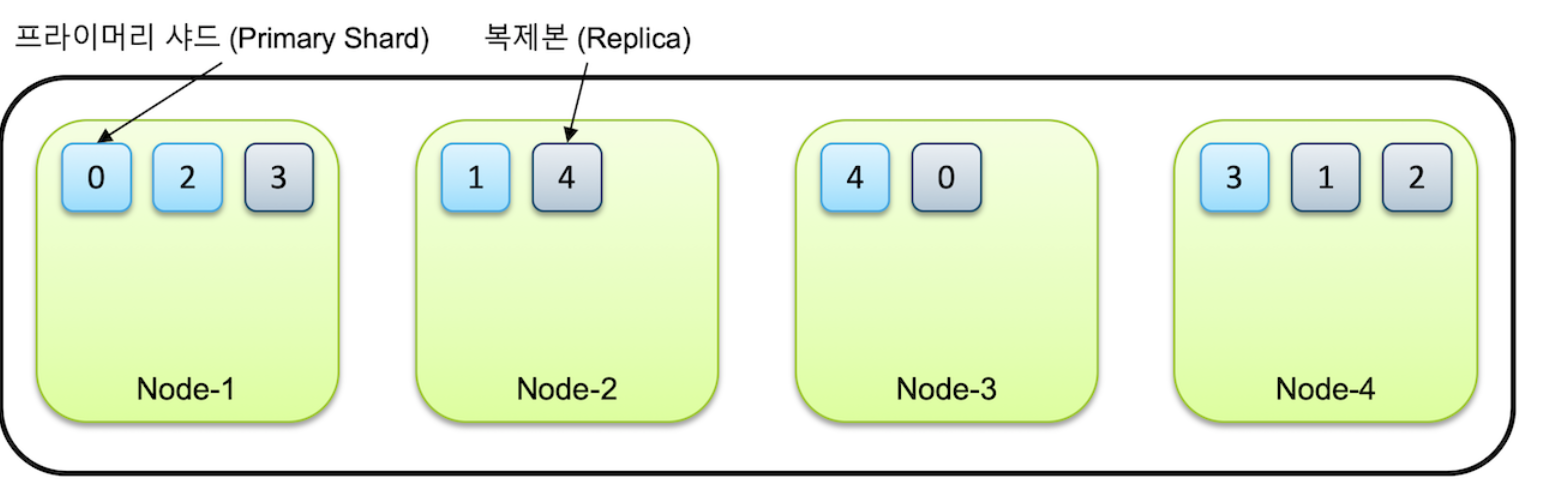
elastic search가 가용성과 무결성을 보장하는 방식.
클러스터에 노드를 추가하면, 샤드들이 각 노드로 분산되고 디폴트로 1개의 복제본이 생성됨.
노드가 1개만 있는 경우, 프라이머리 샤드만 있음.
최소 3개의 노드를 구성하는 것을 권장함.
같은 샤드와 복제본은 같은 데이터를 가지고 있으며 서로 다른 노드에 저장해야 함.
- 만약 Node 3이 사라지면, node 3에 있던 0,4번이 유실됨.
- 하지만 0,4는 node1과 Node2에 남아있기에 전체 데이터는 보존됨.
클러스터는 유실된 노드가 복구되기를 기다림.
타임아웃이 지나 노드가 복구되지 않는다면, elastic search는 복제본이 사라져서 1개만 남은 0번 4번의 복제를 실행함.
역 인덱스

rdbms에서는 fox라는 데이터를 검색하려면, like 검색을 사용해야하기 때문에 데이터가 늘어날 수록 검색할 대상이 늘어난다.
하지만 역인덱스에서는 fox 라는 단어가 어디에 등장했는지 구조를 만들기에 매우 빠르게 검색할 수 있다.
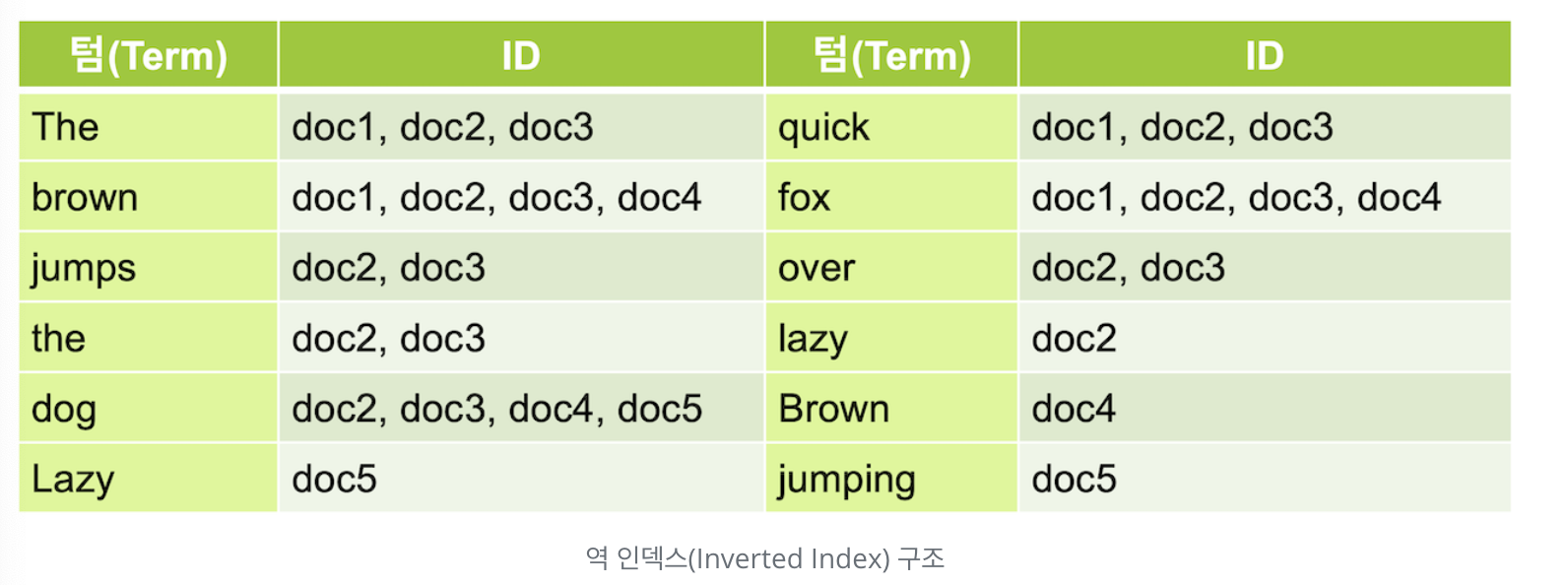
elastic search는 데이터를 입력할 때 저장이 아니라 색인(index)을 한다고 표현한다.
추출된 대상 키워드는 Term이라고 부른다.
텍스트 분석

모든 문자열에 대해서 색인을 한다.
이 색인을 하기 위해 여러 단계의 처리 과정을 거친다.
이 전체 과정을 텍스트 분석(Text Analysis)이라고 한다.
이 과정을 처리하는 기능을 Anaylzer라고 함.
Analyzer는 Character Filter / Tokenizer / Token FIlter로 이루어진다.
텍스트 데이터가 처음 입력되면
1. 캐릭터 필터
- 전체 문장에서 특정 문자를 대치하거나 제거함.
2. 토크나이저
- 텀 단위로 문장을 단어로 분리하는 과정
- 전체 analyzer에서 반드시 1개만 적용 가능.
3. 토큰 필터
- 분리된 텀을 가공해 주는 필터, 커스텀해서 정의 가능
- 예시
- lowercase
- 대문자를 모두 소문자로 바꿔줌. => 대소문자 구별 없이 검색 가능
- stopword
- 검색어로서 가치가 없는 단어(불용어(stopword))
- a, an, are, at, be 같은 단어들
- 커스텀 가능
- ex. 비속어 같은 것도 필터링을 할 수 있을 듯
- 검색어로서 가치가 없는 단어(불용어(stopword))